在當今數據驅動的時代,數據處理與存儲服務不僅是后端開發的核心技能,更是面試中考察候選人綜合能力的重要維度。從文件讀取到復雜數據結構的存儲,再到數據庫的設計與優化,這一系列操作構成了數據處理服務的關鍵鏈路。本文將圍繞這一主題,模擬真實面試場景,層層遞進地探討幾個經典問題,看看你能接住幾招。
第一招:基礎文件讀取與解析
面試官常以實際案例開場:“給定一個包含層級關系的文本文件(如部門-員工樹),如何高效讀取并解析為內存中的樹結構?”
這一問考察基本功。關鍵在于選擇合適的文件格式(如JSON、XML、CSV或自定義分隔格式)和解析策略。例如,對于JSON格式,可使用標準庫(如Python的json模塊)直接加載為字典或列表,再遞歸構建樹節點。對于大型文件,則需考慮流式讀取(逐行或分塊)以避免內存溢出,并利用迭代器或生成器優化性能。解析過程中,異常處理(如格式錯誤、編碼問題)和邊界條件檢查(如循環依賴)是加分項。
第二招:樹結構的內存存儲與操作
當數據讀入內存后,面試官會追問:“如何設計樹的數據結構?支持哪些操作(如查找、插入、刪除、遍歷)?”
這考驗數據結構設計能力。常見方案包括:
- 節點類(Node class)存儲節點值、子節點列表及可選父節點引用。
- 使用字典或映射(如鄰接表)表示節點關系,適用于稀疏樹或需快速查找的場景。
操作實現上,需明確遍歷方式(深度優先DFS、廣度優先BFS)及應用場景。例如,DFS適合路徑搜索,BFS適合層級統計。復雜操作如刪除子樹,需注意內存釋放(在垃圾回收語言中)或引用管理。若面試涉及多線程環境,還需考慮并發安全(如加鎖或使用不可變結構)。
第三招:持久化存儲與數據庫設計
核心難點來了:“如何將樹結構持久化到數據庫中?如何設計表結構?”
這是區分初級與高級開發者的關鍵。常見設計方案包括:
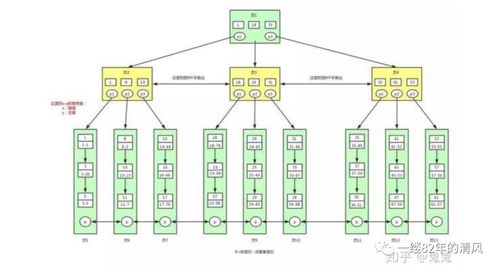
- 鄰接表(Adjacency List):每行存儲節點ID和父節點ID。簡單易用,但查詢子樹需遞歸,效率較低,適合深度不大的樹。
- 路徑枚舉(Path Enumeration):存儲節點路徑字符串(如“1/2/3”)。查詢快速,但更新路徑時需維護一致性,適用于讀多寫少的場景。
- 嵌套集(Nested Set):為節點分配左右值,表示遍歷順序。查詢子樹效率高,但插入刪除復雜,適合靜態或低頻更新的樹。
- 閉包表(Closure Table):額外存儲節點間所有祖先-后代關系。空間換時間,查詢和更新都較平衡,是通用性較強的方案。
面試中,需根據業務場景(如頻繁更新、查詢模式)權衡選擇。例如,電商分類樹可能用閉包表,而組織架構變更頻繁時鄰接表更靈活。
第四招:性能優化與擴展性
進階問題常聚焦實戰:“當樹數據量極大(如百萬節點)時,如何優化查詢和存儲?如何支持分布式環境?”
這需要系統級思維。優化策略包括:
- 數據庫層面:添加索引(如父節點ID索引)、分區表(按層級或子樹分區)、使用物化視圖緩存常用查詢結果。
- 緩存策略:引入Redis等緩存層,存儲熱點子樹或路徑信息,減少數據庫壓力。
- 異步處理:將耗時的樹更新操作隊列化,避免阻塞主線程。
對于分布式場景,可考慮分片存儲(如按子樹分片到不同數據庫節點),但需解決跨分片查詢和事務一致性問題。NoSQL數據庫(如MongoDB的文檔嵌套)也可能成為選項,但需評估其查詢靈活性與數據一致性。
第五招:實際場景與故障處理
面試官可能拋出開放性問題:“如果樹數據在文件中被意外損壞,如何設計恢復機制?如何監控存儲服務的健康狀態?”
這考察工程素養。恢復機制可包括:
- 備份與日志:定期備份樹結構快照,結合操作日志(如WAL)實現增量恢復。
- 校驗與修復:在文件中添加校驗和(如MD5),讀取時驗證完整性;設計修復工具,基于冗余信息(如閉包表中的多重關系)重建損壞節點。
監控方面,需關注指標如查詢延遲、存儲空間增長、錯誤率等,并設置告警閾值。微服務架構下,可通過健康檢查接口和分布式追蹤定位問題。
從文件讀取到樹的存儲,看似線性的流程,實則涵蓋了數據解析、結構設計、持久化、優化及運維的全鏈條。面試中,除了技術實現,溝通思路(如先明確需求再選方案)和權衡取舍(如性能 vs. 復雜度)同樣重要。掌握這些招數,不僅能應對面試,更能為構建穩健的數據處理服務打下堅實基礎。下次面試,你能接住幾招呢?